Sandeep KattepoguExample Spark 3.0.1 Data Transformations in PythonStep-by-step transformations on Kafka data12 min read·Jan 22, 2021----
Sandeep KattepoguBasic Arch Linux Installation on a VM (With or Without Full Disk Encryption)Does “do-it-yourself” have to be so hard?9 min read·Dec 29, 2020----
Sandeep KattepoguBlog: Using VirtualBox as a Cloud Computing ServerFor when you really just don’t want to pay for vSphere6 min read·Dec 1, 2020----
Sandeep KattepoguStreaming Data from MySQL into Apache KafkaCDC-like data pipeline using MySQL binary logs6 min read·Nov 27, 2020----
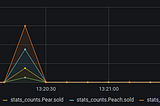
Sandeep KattepoguSending StatsD Metrics and Visualizing in GrafanaCreating a CDC data pipeline: Part 311 min read·Jun 17, 2020----
Sandeep KattepoguStreaming Data from Apache Kafka Topic using Apache Spark 2.4.7 and PythonCreating a CDC data pipeline: Part 210 min read·Jun 12, 2020--2--2
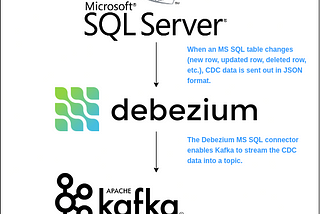
Sandeep KattepoguStreaming Data from Microsoft SQL Server into Apache KafkaCreating a CDC data pipeline: Part 18 min read·Jun 9, 2020--1--1
Sandeep KattepoguGreenplum 6.7.1 on AWSHow to install a three-node Greenplum Database cluster with segment mirroring5 min read·May 15, 2020----